OpenFaaS accelerates serverless Java with AfterBurn
Update:
AfterBurn is now deprecated and Java is supported in the official OpenFaaS templates. Java comes to the official OpenFaaS templates
Feel free to read the original blog post below.
Original blog post
OpenFaaS is a framework for building serverless functions with the power of Docker or Kubernetes. It's cloud native and has Prometheus metrics built-in.
Pictured: Grafana dashboard hooked-up to OpenFaaS during my Dockercon demonstration
Since the initial versions of OpenFaaS we've been able to make anything a serverless function by use of our Function Watchdog. Even pre-cloud utilities like ImageMagick and ffmpeg that have served the Linux community for over 20 years. We do this by forking one process per request in a similar way to how CGI works. This blog post shows how AfterBurn functions can accelerate the throughput of functions with slower initialisation times or burn-in like Java on the JVM.
New to OpenFaaS? Watch the presentation to the CNCF Serverless Workgroup here.
Function Watchdog
First a diagram of how the OpenFaaS Classic Watchdog works:
Function Watchdog flow diagram
The Function Watchdog which is written in Golang is embedded in your container and becomes the entry point or first process. The watchdog then listens for incoming requests and marshals the header and body into the function via STDIN and STDOUT.
This mechanism is what allows any process to become a function. Even /bin/cat or cal can become a function with OpenFaaS - we're working with pipes so binary data is fully supported.
Here's ImageMagick in action resizing an image to 50%:
Need to do image processing? Checkout this Serverless ImageMagick function from the @open_faas CLI - https://t.co/zv5DCtM98O 👌 pic.twitter.com/szZXRzAg3z
— Alex Ellis (@alexellisuk) August 27, 2017
Image Magick on OpenFaaS
How quick is this?
Well if you are running in an language with a low start-up time like Python, Golang or .Net Core then we're talking 10-30ms.
Let's be clear - OpenFaaS runs any binary or programming language on a Windows or Linux back-end.
Let's look at some benchmarks I ran on Packet's bare-metal servers with Ubuntu 16.04, Docker Swarm 17.05 and OpenFaaS 0.6.2.
I used the FaaS sample functions to benchmark the total execution time to fork and execute a new process in various programming languages. I also included a third-party result from a recent blog.
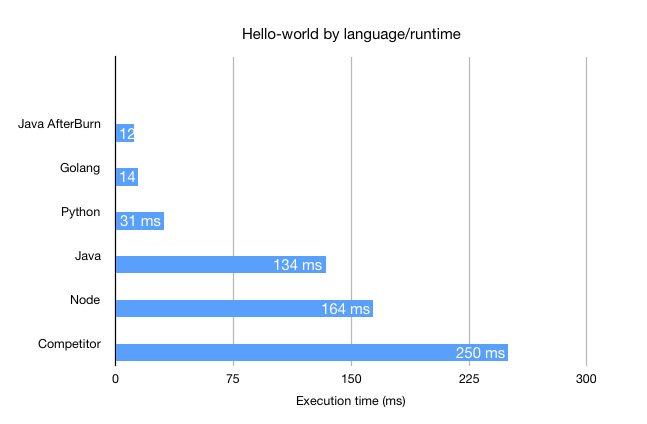
We see that Node.js (164ms) and Java (134ms) have the slowest start-times where as Golang (14ms) and Python (31) are much quicker. The third-party result comes in with a hefty 250ms.
I've included a result for the Java AfterBurn function - here it comes in the quickest at 12ms. It's around a 10x improvement. But what does that mean?
Well if you are running intermittent or slow functions then you may not benefit from the optimization, but if you are expecting very high throughput then it looks a bit like this:
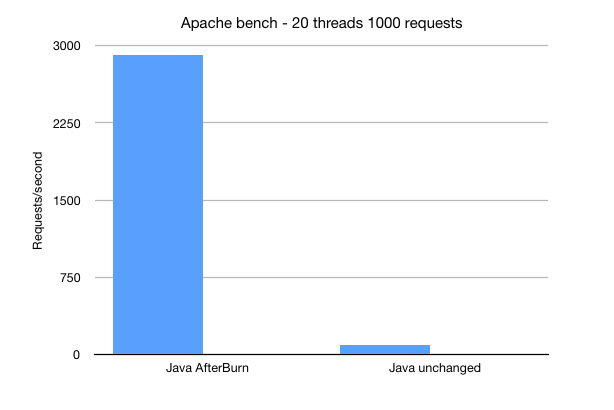
No - that isn't wrong, we're seeing nearly 3000 requests per second vs around 91 from forking a Java JVM per request.
The results from apache-bench are single-threaded and I also turned auto-scaling off. This throughput would be even higher across a multi-node low-latency cluster.
When you begin to load a machine learning model into memory we start to take a small hit for each request. We could optimize it or just run it on the built-in queue provided by NATS Streaminig.
AfterBurn
The Function Watchdog is going to start offering a second mode called: AfterBurn. AfterBurn is where we fork your process once then keep it around for subsequent requests meaning that you can make your functions run faster. This technique is not new and Wikipedia places it around the 1990s.
FastCGI did not take off and was replaced by HTTP, their site has even been taken down meaning the Internet Archives is the only way to find out about it. For historical reasons Golang appears to have a library for it.
So AfterBurn takes the best of FastCGI (reusing a forked process) and the best of HTTP (an easily-parsed well-known text format) and combines them to produce substantial speed boosts for slow functions or JVM-based languages like Java.
Comparison chart
How do I try this?
Get started with OpenFaaS
You can get started with OpenFaaS with our introductory blog post, writing your first Python function or heading over to the repo to Star the project and show your support.
If you'd like a brief conceptual overview and demo then you can watch the recording of the presentation to the CNCF Serverless Workgroup here.
Optimizing with AfterBurn
As a Computer Science student at the University of London I was taught not to optimize unless it was really necessary.
Michael A. Jackson in his book "Principles of Program Design", Academic Press, 1975 says:
We follow two rules in the matter of optimization:
Rule 1: Don't do it.
Rule 2 (for experts only). Don't do it yet - that is, not until you have a perfectly clear and unoptimized solution.
Therefore once you've run benchmarks on your functions, have tried running in asynchronous mode and with faster hardware or bare metal you decide to use AfterBurn.
Nathan Goulding who heads up Packet's engineering team suggested applying CPU tuning via scaling_governor and intel_pstate ramp things up even higher. With powerful hardware available at low rates in spot markets - optimizing software needn't always be the first port of call.
AfterBurn involves writing a small HTTP parser for your target programming language. We've started with Java, Python (for machine learning), Node.js and CSharp. If you'd like to start using AfterBurn get in touch with us on Slack or GitHub and we'll help you get up and running.
- Is HTTP the only suitable protocol?
Along with the HTTP format JSON streaming is also popular as well as GRPC. For most languages a HTTP parser is already built into a standard library or you can write one easily.
Join us on Slack and GitHub
Start Watching the OpenFaaS project on GitHub for all the latest updates, releases, issues and pull requests.
The best way to get involved or ask questions is to join us on Slack. Just email: alex@openfaas.com.