Local Qwen isn't a worse Opus, it's a different tool
We've all heard people say that local Qwen 27B or 35-A3B is "near-Opus level", but I have receipts from a software business and open source projects, and am here to be transparent with you.
This post is long-form for a reason. It's not a cursory glance, an unsubstantiated claim on X about cancelling Claude Max, or a hobbyist report from a model running at single-digit tokens per second with a 32K context window. It isn't written by a famous CEO tweeting about coding from an airplane.
It's my journey as a founder in a small software business, where local models have produced real, caveated value. I have skin in the game, but no incentive to push either cloud or local models, and a strong desire for local models to become capable and reliable.
I'll cover how the card paid for itself in the first two or three months, how it keeps serving our specific business use case, why I still can't trust it unsupervised, and Qwen's worst trait: the infinite loops and hallucination risk. These show up most when you quantize it down to fit a consumer GPU.

Figuring out the power connectors for the RTX 6000 Pro
On my use case for AI
My journey as a maintainer and founder started with OpenFaaS - built completely by hand, as was all software in 2016 up until recently. That meant laying down the core of the project on my own, then inviting others to participate through community - not because I couldn't do it on my own, but because my goal was to build a successful open source project. Around 2017 I tried to fund my time by joining VMware, and in 2019 after changes in the market, I needed a way to fund the work myself, so moved towards open-core and built a bootstrapped company. Today our small team maintains OpenFaaS, SlicerVM - AI sandboxes and "the missing API for Linux", Actuated.com - self-hosted CI runners for GitHub/GitLab, and Inlets.com - self-hosted HTTP/TCP tunnels.
These products are built around low-level infrastructure and Linux primitives: containers, Firecracker microVMs, network protocols, tunnels, CLIs, and Kubernetes. If you squint, they're all opinionated infrastructure products focused on: efficiency, user-experience, control and autonomy. They're written in Go, and some have React-based UI components, landing pages, docs, agent skills, and CLIs. Along with the code, we also provide the best-in-class support, because we are lean and willing to do things that don't scale to help customers.
I've been using AI tools for as long as they've been available - from tab completion in VS Code in the early days, through to getting ChatGPT to generate chunks of code, or find bugs, to living in tmux 12 hours per day. I found myself in tmux so much of the time that I wrote a free tool Superterm.dev to keep track of my sessions, notes, and to get visual feedback from coding agents. Over that time, I've seen the capabilities go from "reduce boilerplate" to "design, architect, and test end to end". It's Claude or Codex that do the majority of my work, and whilst I insist on doing my own writing, I rarely write code by hand - as much as it pains me to say that.
A turning point for frontier intelligence
I'd say it was roughly between November 2025 and January 2026 that we saw a turning point. Many developers on X started to espouse Claude Opus as having changed and how it was now capable of doing all of their work. Manual coding turned bad as quickly as milk sours left out the fridge. The costs of the top-end coding plans settled at roughly 200 USD / mo for individuals. A real number, but tolerable for the value they generated. Even today, if you avoid too much unattended work, you can make it last through the 5 hour limit, and weekly limit if you're careful.
What makes local models interesting
There's an argument that says: "Why use anything less than the best you can afford?"
The year of 2026 certainly is a new frontier: we find ourselves in a place where any idea can be cloned overnight by someone you've never heard of with a subscription in a developing nation. I've seen it happen to our SlicerVM product (originally written by hand in 2022) and Superterm (new in 2026, 100% written by coding agents). It's not to say that a vibecoded clone is a 100% equivalent of a well engineered and architected solution with an experienced team supporting it, but a market where the cost of software went to nil - free and good enough can be all that matters.
So in such a competitive landscape, why limit yourself to something that's worse? Isn't that an opportunity cost? Isn't that risking your livelihood?
There are estimates that the leading models contain between 0.5-2T parameters. That's not just "marginally more" or a "few times more" than the best in class for local hardware - that's on a different level. The parameter count is a rough proxy for capacity, knowledge, and reasoning ability. Yet somehow, even a tiny dense model like Qwen 3.6 27B is able to score a reputable benchmark of 77.2 on SWE-Bench Verified vs 88.6% from Claude Opus 4.8.
So you could be forgiven for taking to X and shouting loudly that "local is only 12% behind SOTA" and many have, including engaging one-shotted demos of space invaders. You may go as far as claiming that a single 6-year old GPU can replace your 200 USD / mo ChatGPT Pro subscription, and indeed many have made that claim.
Benchmaxxing
Benchmarks are a moving target, and since they're widely available, it's possible to educate and tune a model to obtain a higher score than they would otherwise on these tests. The classic SWE-Bench Verified benchmark is based upon a set of Python issues across a number of Open Source projects. Python has threads, and async, however most code you run into is single-threaded and synchronous. In contrast, we write distributed systems in Go, where channels, contexts, and structs span across a large execution domain.
Cost
There's a very popular take "local models aren't about cost" and that comes from a position of privilege. Individuals can use coding plans that provide high amounts of usage through a working day for 200 USD / mo. On that basis, you are getting SOTA level intelligence, the best chance of something working and being of quality, of finding that bug, or generating that landing page.
Coding plans are clearly subsidised, just look at what happened to GitHub Copilot plans. They started off by giving away 1500 requests for 39 USD / mo and you could make that last a very long time for pennies. Something that was undisclosed changed at GitHub/Microsoft/Azure, and they moved everyone over to token-based pricing and the backlash was huge. The true cost had been hidden for so long, we'd become accustomed to it.
Now, if you're paying for tokens on API rates, the breaking point comes sooner than many of us realise. Recently, Uber capped spend to 1500 USD / mo per developer per tool. The median salary at Uber is 330k USD annually, so if a developer used two tools to the maximum extent, it's roughly 12% of their annual compensation.
So for heavy use, loops, agentic analysis, in-product capabilities deployed through SaaS systems, open weight, or local models can provide serious value. It's not fair to rule out cost, but for many it's not about that.
Sovereignty and privacy
We work with various enterprise customers that take data controls very seriously. If you squint at our product line, we're all about privacy and sovereignty. OpenFaaS runs functions on your infrastructure, with your limits and preferred languages, and events. SlicerVM runs microVMs not on some abstracted cloud-based bare-metal, but on your own kit, even your MacBook. Inlets runs tunnels where you can control the tunnel client and server with 100% privacy. Actuated takes the arduous parts of GitHub Actions away and says "install an agent on your machines and forget about it".
So naturally, we are drawn to local models - both from our core values and beliefs about how the Internet should be, but through obligations.
You may not hold these beliefs, you may not handle any customer data, but if you live outside of the US, the removal of Anthropic's Fable 5 model overnight might have come as a shock. In other words, there is serious vendor risk, and many of us are addicted to the source.
Local models are the solution to "What if the frontier labs do X?"
Tempering the blade
I said that local models are not the same tool as SOTA. What did I mean by that?
I build furniture using hand tools, and occasionally just like I'll release an open source project to scratch an itch, I'll make an edge tool like a chisel, a grooving plane blade, a scratch awl, a Sloyd knife for carving.

Tempering a Japanese style marking knife on the back of a heated file, until it hits straw colour.
There are two ways to work with steel depending on how much you can invest. Forging is taking a raw piece of steel, heating it up and smashing it with a hammer into the form you need. It's seen as the most pure and honourable way to work - the "real way". Then for smaller items, "stock removal" is much more approachable. It involves taking sheet steel, cutting out a shape and grinding in a bevel or a point.
But that's just the shaping. You then have to heat the steel up, and quench it in oil or water. This makes the steel become extremely hard, so hard that if you dropped it - it would shatter into pieces. So we have to scrub off the black scum, and heat it up again, watching for a rainbow of colours. If we go one shade past where we need, we have to start the heat treating all over again.
Our team's experience of local models is exactly like missing the temper colours. The model is running so hot, that it shoots past the goal and starts looping. Nothing can fix it, other than closing down the harness and hoping the cleared context will give a different result.
I'd never leave a blade tempering unattended, just like I'd never leave Qwen 3.6 27B working on a long horizon task. For steel the workaround is using a kiln, or temperature controlled oven to remove variability.
That Sloyd knife we forged could be used to knock in nails, but you're likely to cut your hands and ruin the edge at the same time. Let's go back to the start, if it's a different tool, what is it good for?
What I was looking for
I was looking for all of the things we covered in the previous section: privacy, fixed costs and protection against vendor risk. Where I got and continue to get let down is where I treat a local model inside opencode in the same way I treat Claude or Codex. It's almost creepy how long they can work fully unattended whilst making real progress towards a goal.
I can paste in something like: "Eoin told me he has been running Slicer VMs in a loop and ran out of FDs. He suspects VSock" and then after a couple of minutes Claude replies "Now I see the full picture: You're doing X, you need to do Y". I say "do it and test it end to end on my mini PC" and after any period of time - 5 or 15 minutes, I can raise a PR, have it code reviewed automatically, and then tell Claude to read it and iterate again.
It's a wonderfully efficient loop for a small team like us that manages multiple products and works very closely with enterprise and community users.
Sharp lessons from a 3090

I started off with a single 3090 card in 2023, and quickly realised I needed another to be able to load models and have sufficient context. Nothing about local models from 2023 is worth covering here, other than they were so hard to use that I gave up on them. Qwen 3.5 was the first time I saw real work being done by agents.
I could load a model into either card in Q4 quantization with 200k context (also quantized) and get it to do small tasks, when guided. I still remember how quickly that went south. I told the model "Explore this machine from every angle, complete a forensic report on the machine and how it's used" - Claude would have shrugged that off. Qwen started reading every single file on my machine one by one, filled its context, then hallucinated the filenames and even tool calls ~/faas-netes became ~/faaned. Stepping back, I was able to get a really lucid report by scoping the task "Take a quick look around this machine, tell me who uses it and what for" and that ran at roughly 40-50 tokens per second (generation).
A 27B model simply doesn't fit at full fidelity into 1x 3090 card, so the knobs and dials are: compression level of the model's weights (quantization), length of the context, and compression level of the keys and values of the context.
There's a well known rule of thumb that bad things start happening at Q4_0 on the keys part of the KV cache. The most aggressive I've ever been is Q8_0 for keys and Q4_0 for values.
The 3090s were a constant source of headaches - I had to quantize well below where I was comfortable. One of the cards would only show up if I crossed my fingers when turning it on. Even reboots wouldn't cure it - I had to A/C power off and remove the power cable each time for 30 seconds.
As a quick update: I did find that going back to the last build of the proprietary driver fixed all the issues we had with reliability, and was the only driver that allowed us to disable the GSP firmware which was the source of the issues on one of the cards.
My latest experiment was setting up vLLM (the gold standard for production and concurrent serving) and even with an NVLink (175GBP) and tensor parallelism turned on, it was 3 tokens/second slower than llama.cpp during generation for an equivalent setup. With vLLM, we still saw looping, and loading the weights took a few minutes rather than single-digit seconds.
vLLM is the right choice for production-scale serving with continuous batching and many concurrent users. But in a prosumer setup like ours, the trade-off is more nuanced. We're not trying to replace Claude Max subscriptions for a team of five; we're trying to get fast, reliable inference for a small number of known workflows, where startup time, simplicity, and single-user latency matter more than aggregate throughput.
I was spending more time on making them work than the results.
Big spender
We offer support contracts to enterprise companies using our products, and when a ticket comes in we are incentivised to resolve it as soon as reasonably possible. I thought that getting a card that would make all the niggles go away would fix local models, and customer support was worth the risk.
We dropped around 12000 USD on an RTX 6000 Pro Blackwell edition with 96GB of VRAM. Even a couple of months on, the price has increased to around 15400 USD so adding a second becomes much harder to justify. You can't just "slot another card in" to a consumer machine. There are many concerns from PCI lanes, to bandwidth, to card spacing, and the draw on the PSU.
It was a calculated bet, and it has paid off, but not because it replaces our Claude subscriptions - it can't do that.
Painless customer support, without leaking customer data
Many operators at enterprise companies are highly capable and skilled, but they're held back by manual procedures and practices. Sometimes you're lucky and someone will work through every point in a troubleshooting guide and tell you what they got wrong. Other times, you're 150 replies deep into an email chain and they've still not run that one command that would answer it all.
So we wrote "diag" a CLI tool that is easy for operators to run and that captures a complete snapshot of an OpenFaaS installation on Kubernetes. They can then email this dump to us and we can run it through an airgapped local model, in an ephemeral VM created by Slicer. You can read more about the issues we found in Introducing: Painless support and hands-off architecture reviews over on the OpenFaaS blog.
Revenue recovery
A renewal came up recently, and only because I fed the telemetry database into a local model, did we find out they'd been under-reporting licenses and under-paying by about 4-5x for over 12 months. That revenue recovery alone paid for the card.
There's no way I would have in good conscience ran the telemetry dump or a customer's diag output through any cloud plan, regardless of their stance on data retention. This is a good time for me to cover near- and far-east coding plans - caveat emptor - I'm yet to find one that doesn't take a privileged position on your IP - training and ownership rights for inputs and outputs. ChatGPT Pro and Claude Max can be configured for a 30 day retention period, but even that level likely invalidates your contracts with customers.
Sometimes I've given GPT or Opus the schema for the telemetry table and had it write an AGENTS.md that the local model is most likely to follow. Our data is reported several times per day, from multiple high-availability replicas, so it can't just be summed up across a 24 hour period. With earlier iterations of the model, I saw it fail at arithmetic - 27.3K counted as 273,000. It was only because I was thoroughly checking its work that I caught it out.
Another time, the model inferred a customer was likely to churn because they had a small number of functions. It completely ignored that the customer ran that smaller number of functions many times per day. So often it's better to have them focus on analysis, not interpretation.
Our current setup
I'm a big supporter of folks like Jack Rong and Kyle Hessling who have worked on fine-tunes of open weight models like Qwen. Qwopus attempts to layer Chain of Thought traces on top of Qwen to make it better at reasoning and coding. They do this to help the community and because of a deep belief in local AI.
In our team we run both the latest generation of Qwopus, and the base 27B Qwen 3.6 model on the RTX 6000 rig. Over time this changes - as new finetunes come out, as new point releases of Qwen drop and as we land upon new edge-cases and limitations. Up until very recently, we ran with thinking turned off completely, and have only recently added it back in which coincided with seeing more looping.
The models are served by two independent llama.cpp instances, which means they retain full context length. The default answer to "concurrency" is to run --parallel 2 but this halves the available context.
$ nvidia-smi
Wed Jun 17 11:56:03 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 590.48.01 Driver Version: 590.48.01 CUDA Version: 13.1 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA RTX PRO 6000 Blac... Off | 00000000:01:00.0 Off | Off |
| 30% 32C P8 15W / 600W | 85937MiB / 97887MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 2265 C ...ma.cpp/build/bin/llama-server 31198MiB |
| 0 N/A N/A 2544 C ...ma.cpp/build/bin/llama-server 54718MiB |
+-----------------------------------------------------------------------------------------+
llama.cpp is built from source and kept up to date weekly, or as required. The build from source is required in order to add support for Nvidia GPUs.
Here's our command for a single instance of Qwen with full context length and full quality context.
#!/bin/bash
~/llama.cpp/build/bin/llama-server \
-hf unsloth/Qwen3.6-27B-MTP-GGUF:UD-Q8_K_XL \
--alias Qwen3.6-27B-Base \
--host 0.0.0.0 \
--port 8085 \
-ngl 99 \
-c 262144 \
--cache-type-k f16 \
--cache-type-v f16 \
--flash-attn on \
--parallel 1 \
--threads 16 \
-b 4096 \
-ub 2048 \
--jinja \
--reasoning-budget 2048 \
--temperature 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 1.1 \
--reasoning on \
--spec-type draft-mtp \
--spec-draft-n-max 6 \
--chat-template-kwargs '{"preserve_thinking": true}' \
--chat-template-file chat_template.jinja \
--reasoning-budget-message "reasoning budget consumed, time to answer now"
We get about a 93% acceptance rate on our speculative decoding from MTP, and the speed increases from a stable 67 tok/s to 130-200 tok/s sustained over long periods. It feels faster than using a cloud model.
It's important to follow the instructions from the model card when tuning llama.cpp. There are often reasons why a certain temperature has been selected by the lab. For instance, with the Qwopus fine-tune, it works best with thinking turned off and the temperature really hot at 0.85-1.0.
About that looping
Recently I've been tuning it to try to avoid looping, goes back to that tempering analogy. You can't just leave this model to work on long horizon tasks.
I asked Qwen what commands we should add to faas-cli, and it came back with some reasonable suggestions, but got stuck and kept repeating them over and over, burning 600W of my electricity for a good half an hour.
58. faas-cli function import - Import functions from a YAML file or URL.
59. faas-cli function export - Export deployed functions back to a stack.yaml file.
60. faas-cli function scale - Manually scale function replicas without redeploying.
61. faas-cli function rename - Rename a function in-place.
62. faas-cli function diff - Compare local stack.yaml with what's deployed - show differences.
63. faas-cli function import - Import functions from a YAML file or URL.
64. faas-cli function export - Export deployed functions back to a stack.yaml file.
65. faas-cli function scale - Manually scale function replicas without redeploying.
66. faas-cli function rename - Rename a function in-place.
67. faas-cli function diff - Compare local stack.yaml with what's deployed - show differences.
68. faas-cli function import - Import functions from a YAML file or URL.
69. faas-cli function export - Export deployed functions back to a stack.yaml file.
70. faas-cli function scale - Manually scale function replicas without redeploying.
71. faas-cli function rename - Rename a function in-place.
72. faas-cli function diff - Compare local stack.yaml with what's deployed - show differences.
Build · Qwen3.6-27B-Base toilgate
The same thing happened when I asked it to "add --json to all get and list commands" - it was convincing for the first one or two and even wrote tests.
Then because --json is machine readable, faas-cli needed to stop printing warnings about insecure TLS when using a http:// remote endpoint. Qwen couldn't work out how to do this so I told it to write a reverse proxy in Python and call that instead. The first version looked plausible but had bad indenting. When it realised the issue, it corrupted the file, and kept complaining that it didn't know how to fix it and was stuck in a different kind of loop. It just wouldn't give up, but went progressively off the rails.
Han from my team has reported very similar looping - mostly the second kind. The model or agent is stuck, at the edge of its ability and won't ask for help. For me, I've mainly hit the former, which is arguably worse and means I rarely trust it beyond the telemetry and diag work for customer support/renewals.
Measuring and distributing access
To begin with, I set up a single inlets tunnel and hoped the agents wouldn't clash. Two agents hitting the same llama.cpp instance with unrelated contexts means each request invalidates the other's cached prefix — so the full prompt gets re-processed from scratch every time, a thrashing latency you don't want to feel often. We were still doing most work on coding plans then, so it wasn't yet a real problem.
Distributing that setup was simple: edit opencode.json and add the URL and token, then copy that file onto your various machines or Slicer VMs.
But as soon as another person uses the model, it stops being a prototype. Who's on which llama.cpp instance? How much are they using? Which model? What has that cost us in electricity? What happens if that person leaves the team? How do we add in another model for the team?
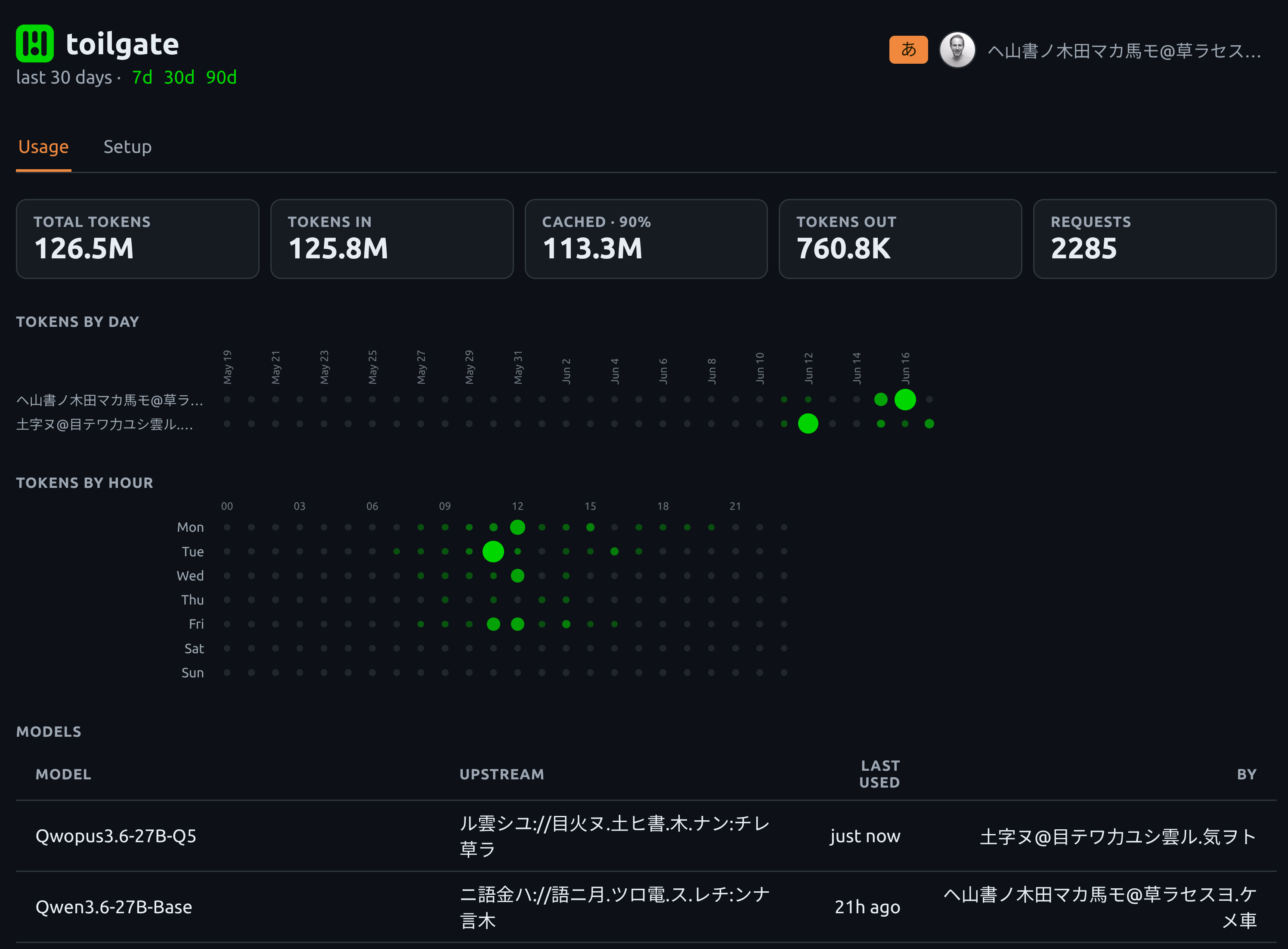
Toilgate is 100% vibe-coded and too much work to open source. If you like the idea, feel free to make your own.
Rather than manually editing my opencode.json file, and sending that to various team mates, I decided to write a provider for opencode. It would manage the available models from the stable base through to more experimental Qwopus variants that were quantized. Just run opencode - go to the model picker and select toilgate then whatever you want to use.
Two Shelly Plus Plugs are monitoring the power consumption at the wall to give me a better idea of actual costs. The RTX 6000 Pro will pull 600W during inference and is relatively quiet, the two 3090s are closer to 750W combined and extremely noisy.
The wrong comparison
The trap once you can measure is comparing the input/output costs per million tokens to OpenAI's API pricing for GPT-5.5. That's the wrong comparison for the current capability. It's more about understanding the ongoing costs, which I'm bearing personally since the machine is in my house, for work that's not suitable for a cloud model.
This is where "local AI" turns into an operations problem. You need identity, access control, metering, quotas, model routing and power monitoring. The harder part we keep coming back to is the reliability of the agent/model combination, keeping up with innovations like MTP, and ensuring enough uptime for people who have started to depend on the model being available.
Wrapping up
Whilst local Qwen is not "near Opus levels", and I hope I've demonstrated that enough in the post, it is of value for certain tasks and workflows. It's also incredibly early, and it can only get better from here. Qwen 3.5 was probably the first model that gave us results we could use. There are rumours of 3.7 coming out soon, which I'd expect to be an iterative improvement - not a revolutionary one.
Concrete things that help:
- Match the local model and harness to specialised tasks - customer support, well bounded maintenance, and end-to-end testing
- AGENTS.md - when I added detailed instructions to alexellis/arkade, I found that the local model could add new CLIs more quickly and efficiently than human contributors, and would test its work
- Pay attention to the tuning notes on the model card - temperature, context settings, and quantization all matter. Beware of very low quantizations.
- Local models can quickly read and explain codebases, even if they can't write them - this is a superpower
- Fine-tunes like Qwopus exist - be willing to experiment to find the right model
- Agent Skills can help immensely - we had a local agent set up Slicer completely from scratch on a new mini PC. It even gave feedback on the usability of
slicerCLI which we integrated - Normalise running the same task with a local and cloud model - sometimes you'll be disappointed, other times you won't believe your luck
- Don't hand it long-horizon, unsupervised agentic work - that's where it loops, and even our almost 15k USD card couldn't fix that
You'll notice I've not mentioned 70B models - most are genuinely old at this point, generations behind. The 35-A3B variant of Qwen tends to be popular because it looks faster on MacBooks - the reason is because there are only 3B active parameters at generation time, I'd much rather trade speed for the best quality I can get. There are much bigger models like GLM 5.2, Kimi 2.7, Minimax M3 and Deepseek V4 Flash. They can run on some local rigs, but you're often talking about 4-6 RTX 6000 Pro cards to even load a quantized version of the model, which puts them out of scope for us.
As a consumer, I don't know what the next step up would take - whether it shifts into enterprise hardware, or whether there's a place for 27B dense models, but today they are not cut out to write Go all day long. Their limited knowledge and attention shows up immediately in code review. Whilst Go code can be written, and may even have working concurrency, our experiments got shut down very quickly when we found Qwen would not follow instructions to be brief, and went into spurious detail on automated code reviews, and hallucinated concurrency issues and race conditions. The relatively unsexy Grok Coder Fast 1 was cheaper, and faster and served us well for months before being deprecated.
You can read about our code review bot here and about painless customer support and architecture review for OpenFaaS here.