GitHub Actions as a time-sharing supercomputer
The time-sharing computers of the 1970s meant operators could submit a job and get the results at some point in the future. Under the guise of "serverless", everything old is new again.
AWS Lambda reinvented the idea of submitting work to a supercomputer only to receive the results later on, asynchronously. I liked that approach so much that in 2016 I wrote a prototype to unlock the idea of functions but for your own infrastructure. It's now known as OpenFaaS and has over 30k GitHub stars, over 380 contributors and its community have given hundreds of blog posts and conference talks.
There's something persuasive about running jobs and I don't think it's because developers "don't want to maintain infrastructure".
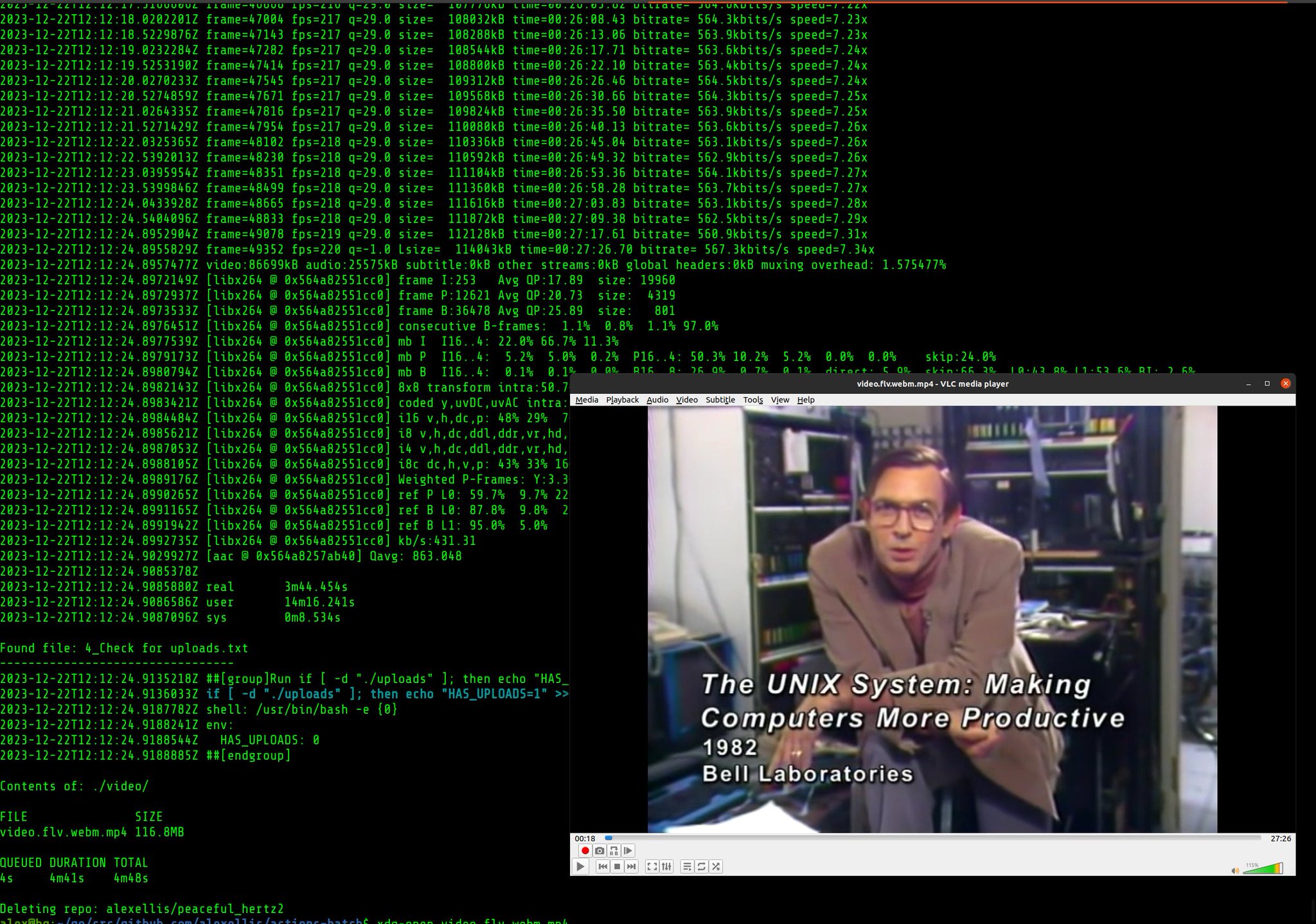
"I know this, it's a UNIX system"
See my Twitter thread as I built the actions-batch tool.
Prior work
I mentioned OpenFaaS and to some extent, it does for Kubernetes what time-sharing did for mainframes in the early 60s and 70s.
You can write functions in application code or bash and wrap them in containers, then have them autoscale, scale to zero, with built-in monitoring an a REST API for automation.
For a couple of examples of bash see my openfaas-streaming-templates or the samples written by a Netflix engineer for image and video manipulation.
With OpenFaaS you write code once and then that acts as a blueprint, it can be scaled, triggered by cron, Kafka and databases, run synchronously or asynchronously with retries and callbacks built-in to receive the results.
But sometimes all you want is a one-shot task.
In the Kubernetes APIs, we have a "Job" that can be scheduled. So my initial experiments involved writing a wrapper for that, which we use for customer support at OpenFaaS.
Fixing the UX for one-time tasks on Kubernetes
I'd also had a go at something similar for Docker Swarm which companies were using for cleaning up database indexes and running nightly cron jobs.
actions-batch
actions-batch is an open-source CLI available on GitHub

An ASCII cast of building a Linux Kernel, and having the binary brought back to your own computer to use.
So with the comparison to OpenFaaS out of the way, and some prior work, let's look at how actions-batch works.
- A new GitHub repository is created
- A workflow is written which runs "job.sh" upon commits
- When a local bash file is written to the repo as "job.sh", the job triggers
That's the magic of it. We've created an "unofficial" API which turns GitHub Actions into a time-sharing supercomputer.
The good bits:
- You can include secrets
- You can fetch the outputs of the builds
- You can use self-hosted runners or hosted runners
- Private and public repos are supported
Build a Linux Kernel and bring it back to your machine
Let's say you're running an Apple MacBook, and need to build a Linux Kernel? You may not have Docker installed, or want to fiddle with all that complexity.
mkdir kernels
actions-batch \
--owner alexellis \
--org=false \
--token-file ~/batch \
--file ./examples/linux-kernel.sh \
--out ./kernels
Then:
┏━┓┏━╸╺┳╸╻┏━┓┏┓╻┏━┓ ┏┓ ┏━┓╺┳╸┏━╸╻ ╻
┣━┫┃ ┃ ┃┃ ┃┃┗┫┗━┓╺━╸┣┻┓┣━┫ ┃ ┃ ┣━┫
╹ ╹┗━╸ ╹ ╹┗━┛╹ ╹┗━┛ ┗━┛╹ ╹ ╹ ┗━╸╹ ╹
By Alex Ellis 2023 - (232d61a253f0805b85d60fecf87f5badbb53047b)
Job file: linux-kernel.sh
Repo: https://github.com/alexellis/hopeful_goldwasser3
----------------------------------------
View job at:
https://github.com/alexellis/hopeful_goldwasser3/actions
----------------------------------------
Listing workflow runs for: alexellis/hopeful_goldwasser3 max attempts: 360 (interval: 1s)
Without installing anything on your computer, in a minute or two, you'll get a vmlinux that's ready to use.
Contents of: ./kernels
FILE SIZE
vmlinux 22.71MB
QUEUED DURATION TOTAL
3s 2m51s 2m57s
Of course, hosted runners are known for being great value, but particularly slow. So we can run the same thing on our own, more powerful infrastructure:
actions-batch \
--owner actuated-samples \
--token-file ~/batch \
--file ./examples/linux-kernel.sh \
--out ./kernels \
--runs-on actuated-24cpu-96gb
In this example, a 24vCPU microVM was used with 96GB of RAM allocated. Of course, you never need this much RAM to build a Kernel, but it shows what's possible.
If you want to know how much disk, RAM or vCPU you need for a GitHub Action, you can use the actuated telemetry action.
Once complete, the repository is deleted for you.
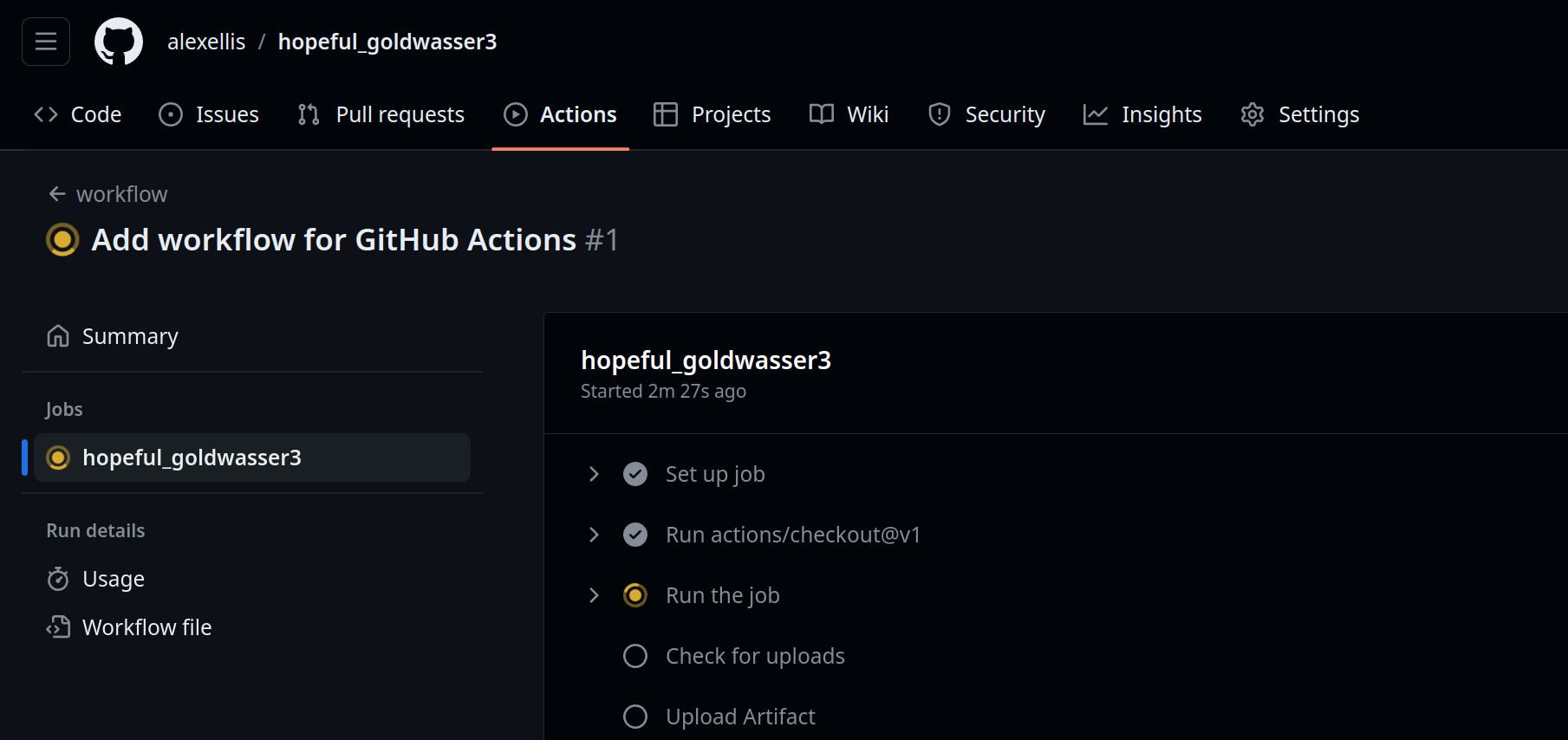
The repository is part of the "batch job" specification
Run some ML/AI using Llama
You can run inference using a machine learning model from Hugging Face.
Here's how to get a Llama2 model to answer a bunch of questions that you provide with 150 tokens being used.
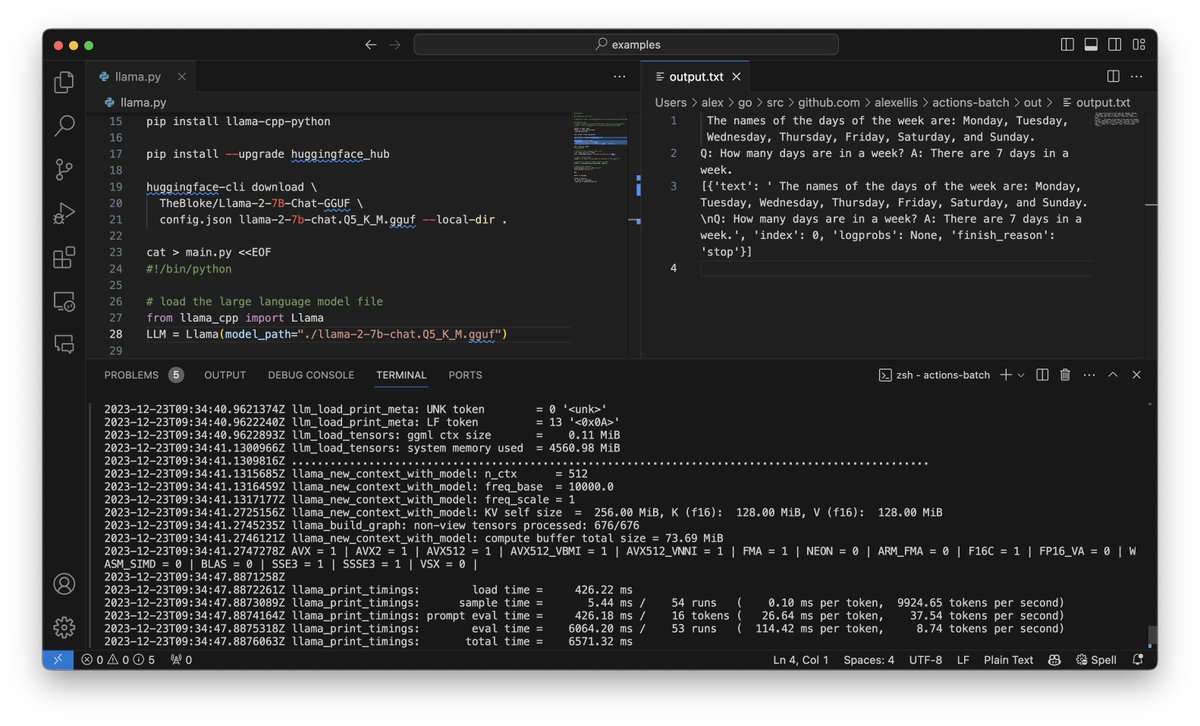
Example of running inference against a pre-trained model
Download a video from YouTube
actions-batch \
--owner alexellis \
--org=false \
--token-file ~/batch \
--file ./examples/youtubedl.sh \
--out ~/videos/
This will create a file named ~/videos/video.mp4 with the UNIX documentary by Bell Labs.
See a screenshot of the results
Since writing the post, I've added an example for Whisper from OpenAI, and run it using actuated.dev so that I could use a GPU in an isolated microVM rather than having to use Docker insecurely. We had to add support for cloud-hypervisor to mount GPUs since this isn't supported in Firecracker.
Imagine you have a folder with a bunch of audio tracks, and you just submit a batch job and get the transcriptions back on your computer when you've had dinner, or come back from the gym? That's what batch job system is all about.
It can take a long time, it can even be quick, but it's about submitting a work item and getting the results later on.
This example was on CPU using a bare-metal host on Hetzner, within a Firecracker VM. The same example will run on hosted runners.
OIDC tokens
You can use GitHub's built-in OIDC tokens if you need them to federate to AWS or another system.
#!/bin/bash
# Warning: it's recommend to only run this with the --private (repo) flag
env
OIDC_TOKEN=$(curl -sLS "${ACTIONS_ID_TOKEN_REQUEST_URL}&audience=https://fed-gw.exit.o6s.io" -H "User-Agent: actions/oidc-client" -H "Authorization: Bearer $ACTIONS_ID_TOKEN_REQUEST_TOKEN")
JWT=$(echo $OIDC_TOKEN | jq -j '.value')
jq -R 'split(".") | .[1] | @base64d | fromjson' <<< "$JWT"
# Post the JWT to the printer function to visualise it in the logs
# curl -sLSi ${OPENFAAS_URL}/function/printer -H "Authorization: Bearer $JWT"
Deploy a function to OpenFaaS using secrets
We've seen how to download artifacts from a build, but what if our job needs a secret?
First, create a folder called .secrets.
Then add a file called .secrets/openfaas-gateway-password with your admin user and then create another file called .secrets/openfaas-url with the URL of your OpenFaaS gateway.
Two repo-level secrets will be created named: OPENFAAS_GATEWAY_PASSWORD and OPENFAAS_URL. They can then be consumed as follows:
curl -sLS https://get.arkade.dev | sudo sh
arkade get faas-cli --quiet
sudo mv $HOME/.arkade/bin/faas-cli /usr/local/bin/
sudo chmod +x /usr/local/bin/faas-cli
echo "${OPENFAAS_GATEWAY_PASSWORD}" | faas-cli login -g "${OPENFAAS_URL}" -u admin --password-stdin
# List some functions
faas-cli list
# Deploy a function to show this worked and update the "com.github.sha" annotation
faas-cli store deploy env --name env-actions-batch --annotation com.github.sha=${GITHUB_SHA}
sleep 2
# Invoke the function
faas-cli invoke env-actions-batch <<< ""
Run curl remotely, if you want to check if it's your network
Sometimes, you wonder if it's your network that's the issue. So you DM someone on Slack: "Can you access XYZ?"
Let the super computer do it instead:
#!/bin/bash
set -e -x -o pipefail
# Example by Alex Ellis
curl -s https://checkip.amazonaws.com > ip.txt
mkdir -p uploads
cp ip.txt ./uploads/
Results:
Found file: 6_Complete job.txt
---------------------------------
2023-12-22T11:59:23.6683796Z Cleaning up orphan processes
Contents of: /tmp/artifacts-2603933045
FILE SIZE
ip.txt 15B
QUEUED DURATION TOTAL
3s 13s 19s
Deleting repo: actuated-samples/vigorous_ishizaka8
cat /tmp/artifacts-2603933045/ip.txt
172.183.51.127
Well 172.183.51.127 is definitely not my IP. It worked.
Build a container image remotely, then import it
Sometimes I build ML and AI containers on Equinix Metal because they have a 10Gbps pipe, and I may well be on holiday or in a cafe with 1Mbps available.
Let's submit that batch job!
#!/bin/bash
set -e -x -o pipefail
# Example by Alex Ellis
# Build and then export a Docker image to a tar file
# The exported file can then be imported into your local library via:
# docker load -i curl.tar
mkdir -p uploads
cat > Dockerfile <<EOF
FROM alpine:latest
RUN apk --no-cache add curl
ENTRYPOINT ["curl"]
EOF
docker build -t curl:latest .
Finally:
./actions-batch \
--org=false \
--owner alexellis \
--token-file ~/batch \
--file ./examples/export-docker-image.sh \
--out ./images/
....
Contents of: ./images/
FILE SIZE
curl.tar 12.37MB
QUEUED DURATION TOTAL
5s 22s 29s
Then let's import that curl image:
docker rmi -f curl
docker images |grep curl
docker load -i ./images/curl.tar
38d2771a5c36: Loading layer [==================================================>] 4.687MB/4.687MB
Loaded image: curl:latest
docker run -ti curl:latest
curl: try 'curl --help' or 'curl --manual' for more information
It worked just as expected.
Let's have a race?
Here, I've submitted the same job both to an x86_64 server and an arm64 server both on my own infrastructure. They'll build a Linux Kernel using the v6.0 branch.
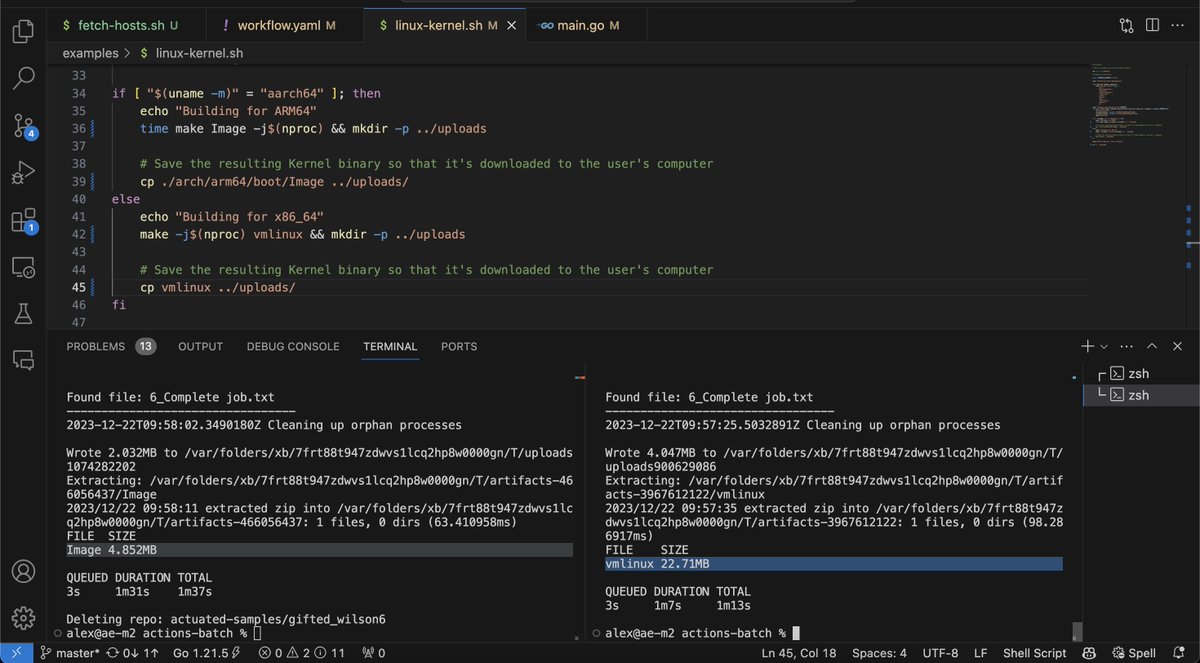
Off to the binary races - what's quicker? vmlinux or Image?
This is also a handy way of comparing GitHub's hosted runners with your own self-hosted infrastructure - just change the "--runs-on" flag.
The youtubedl.sh example is multi-arch aware, and uses a bash if statement to download the correct version of youtubedl for the system. Same thing with the Linux Kernel example you'll find in the repo.
Wrapping up
I hope this idea captures the imagination in some way. Feel free to try out the examples and let me know how it can be improved, and whether this is something you could use.
Q&A:
Where are the examples?
I've added a baker's dozen of examples, but would welcome many more. Just send a PR and show how you've run the tool and what output it created.
https://github.com/alexellis/actions-batch/tree/master/examples
Will GitHub be "angry"?
We often talk about brands and companies as if they were a single person or mind. GitHub is not one person, but the GitHub team tend to love and encourage innovation and have built APIs in order to be able to make use of GitHub Actions in this kind of way.
The most relevant clauses are: C. Acceptable Use and H. API Terms.
Exercise common sense.
Should I feel bad about using free runners for batch jobs?
Use your own discretion here. If you think what you're doing doesn't align with the terms of service, use a private repo, and pay for the minutes.
Or use your own self-hosted runners with a solution like actuated
Could I run this in production?
The question really should be: is GitHub Actions production ready? The answer is yes, so by proxy, you could run this tool in production.
What's the longest job I can run?
The limit for hosted and self-hosted runners is 6 hours. If that's not enough, consider how you could break up the job into smaller pieces, or perhaps look at run-job or OpenFaaS.
Why not use Kubernetes Jobs instead?
Funny you asked. In the introduction I mentioned my tool alexellis/run-job which does exactly that.
How is this different from OpenFaaS?
Workloads for OpenFaaS need to be built into a container image and are run in a heavily restricted environment. Functions are ideal for many calls, with different inputs.
actions-batch only accepts a bash script, and is designed to run in a full VM, running administrative tasks and tools like Docker. It's designed to only run periodic, one-shot jobs or tasks.
Shouldn't you be doing some real work?
Many of the things I've started as experiments or prototypes have given me useful feedback. OpenFaaS was never meant to be a thing, neither was inlets or actuated and people told me not to build all of them.
You may also like
- Telemetry-free metering for right-sizing GitHub Actions
- Explore and debug GitHub Actions runners via SSH - free for GitHub Sponsors
- actions-usage - Understand your usage of GitHub Actions - free CLI that builds a summary of GitHub Actions usage