One of 2016's key buzzwords was serverless - but is anyone sure what that means? Both AWS Lambda and Kubernetes Jobs provide their own solutions in this space, but..
I'm not sure that we have a clearly defined standard on what serverless should look like and how it should behave.
Here are some of my thoughts on serverless based upon what I've seen this year:
- tends involve invoking short-lived functions (Lambda has a default 1-sec timeout)
- does not publish TCP services - often accesses third-party services or resources
- tends to be ad-hoc/event-driven such as responding to webhooks
- should deal gracefully with spikes in traffic
- despite name, runs on servers backed by a fluid, non-deterministic infrastructure
- when working well makes the complex appear simple
- has several related concerns: infrastructure management, batching, access control, definitions, scaling & dependencies
Martin Fowler also maintains a Bliki entry on Serverless if you want to read more.
TL;DR?
Jump straight in!
Updates since original post
Since the original post on 4th Jan development has continued in the FaaS repo and progress has been made towards answering the above questions.
- Auto-scaling up and down of function replicas has been implemented via Prometheus alerts
- A UI has been built to explore functions on the Swarm and their invocation count
- Metrics have been extended with labels per function
- Several contributors have got in touch with PRs and issues
Leveraging Docker and Swarm Mode
An issue was opened on the Docker Github repo on 23rd June just after Swarm Mode was released: Swarm mode should support batch/cron jobs. It speaks to the complexity that is involved in supporting "serverless" functions.
Perhaps instead of trying to solve the entire problem space of "Serverless" with one monolith that covers every avenue we could focus on one or two aspects such as: how to run ad-hoc jobs or how to provide an fluid infrastructure.
Let's talk about: Functions as a Service
After having spent several weeks working with AWS Lambda functions for the Alexa SDK I grew to appreciate the simplicity provided. I uploaded my functions and then Amazon's infrastructure took care of running my code as and when I needed it. Managed services such as AWS Lambda are attractive because they just work and have excellent integration with related services such as S3, EC2, CloudWatch and SNS Queues. Tight integration adds value but also leads to vendor lock-in, so are there other options for private/hybrid clouds?
I investigated what the Docker team had presented on "Serverless" at Dockercon 2016 and started to adapt it to create a Lambda equivalent that could be run on your own hardware using Docker Swarm Mode.
Mark I - API Gateway
I had been working with the Alexa voice SDK service - it allows you to define your own skills for your Amazon Echo/Dot, it will parse the voice invocation into an Intent (action) with a number of slots (parameters). The Alexa service then invokes a HTTPs endpoint or Lambda function with a JSON payload and expects a similar one in response which will be read out on your device.
This seemed like a good place to start democratising the work Ben Frishman showed at Dockercon 2016 called Funker.
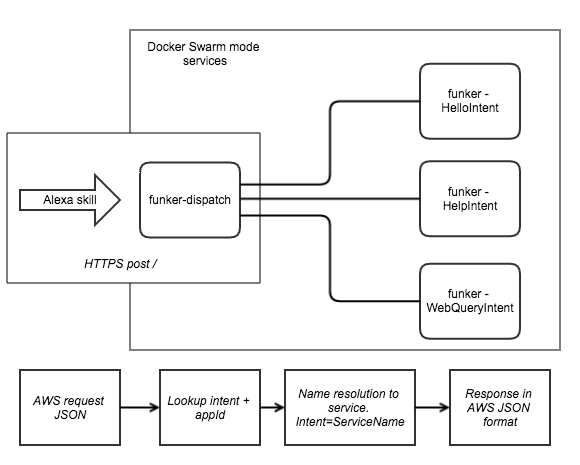
It didn't take me long to figure out what Ben was doing. The basic premise of Funker was that a TCP port would be opened up to accept a single request of serialized JSON and then send back a response.
Pros:
- Libraries were made available in Go/Node.js and Python
- Could be invoked by other containers in the network such as in the Docker Voting example Ben demoed.
- Makes use of Docker 1.13-RC features such as attachable networks.
Cons:
- Language bindings had to be maintained in several programming languages
- The function (container) was killed after every invocation making it slow
- Everything was manual - you had to rely on your functions being set up in advance
- There was no easy way to interact with functions from outside the network (no API gateway or reverse proxy)
- Ben said this was only a PoC designed to be a thought-provoker for the community.
I set about resolving some of those issues and put together a full working demo of an API gateway and hooked it into my Amazon Echo Dot at home. I also wrote code to allow the functions to process more than one request.
The API gateway solution (funker-dispatch) was built out in Node.js meaning that it could run on practically any hardware that supported Docker. For my deployment I chose a Raspberry Pi cluster because it was so cheap to leave running all day.
There were still a few issues:
It was unclear how to control access to various functions or how to categorise the different requests: services.json was my initial attempt at solving this problem.
I still had to maintain all of Ben's funker libraries and I wanted to alter them to be able to serve more than one request per replica.
I wanted to submit my work to Dockercon 2017 Austin, TX as part of a cool hack or black-belt talk. Unfortunately the fact that I'd built on top of the funker work was working against me with my submission. This needed to be new.
Mark II - FaaS
I had a chat with Justin Cormack from Docker's Engineering team in Cambridge and he suggested a twist on the original idea - we would just run processes in containers and use the STDIN/STDOUT pipes in a true UNIX fashion to control flow. I wasn't happy with the TCP sockets either, so that was swapped out for a lightweight HTTP server.
This meant we could create a serverless function out of any process, including
cat. We could even test it withcurl.
Here's the proposal for the new version of Functions as a Service in Swarm Mode which addresses some of the previous limitations.
Function watchdog
- Each container has a watchdog process responsible for accepting requests from an API gateway.
- The watchdog uses a syscall to os/exec so that there is no magic involved
- Input parameters are piped via STDIN
- The output response is read from STDOUT
- The watchdog enforces timing constraints
The functions can be called from any container within the swarm just like with Funker, but we are opting for a standard transport mechanism: HTTP and JSON. This means we only maintain a single version of the watchdog code in Golang.
API Gateway
The API Gateway is your access point to functions when you are running code outside of the Swarm overlay network. It also means that when consuming events such as HTTP POSTs from an external source you don't have to keep writing the same boiler-plate HTTP server code each time.
You can focus on consuming the event and handling it quickly.
Metrics
The Docker engine has adopted metrics collection through a Prometheus format, so FaaS has enabled that too - just point to: http://localhost:8080/metrics/.
Routing is achieved through:
-
/function/{service_name}
-
X-Functionheader of {service_name} -
Or auto-detection for Alexa SDK Intents which invoke the {service_name} of the Intent Name in the Alexa JSON requests.
An example function
So to create a function to stash away webhook requests we put together a simple Go application to write to the working directory:
package main
import (
"fmt"
"io/ioutil"
"os"
"strconv"
"time"
)
func main() {
input, _ := ioutil.ReadAll(os.Stdin)
fmt.Println("Stashing request")
now := time.Now()
stamp := strconv.FormatInt(now.UnixNano(), 10)
ioutil.WriteFile(stamp+".txt", input, 0644)
}
We then construct a Dockerfile and add in the watchdog process telling it what to invoke:
FROM golang:1.7.3
RUN mkdir -p /go/src/app
COPY handler.go /go/src/app
WORKDIR /go/src/app
RUN go get -d -v
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
ADD https://github.com/alexellis/faas/releases/download/v0.3-alpha/fwatchdog /usr/bin
RUN chmod +x /usr/bin/fwatchdog
ENV fprocess="/go/src/app/app"
CMD ["fwatchdog"]
Everything looks like normal except for the last few lines:
ADD https://github.com/alexellis/faas/releases/download/v0.3-alpha/fwatchdog /usr/bin
RUN chmod +x /usr/bin/fwatchdog
ENV fprocess="/go/src/app/app"
CMD ["fwatchdog"]
The fprocess environmental variable contains the program we need to run. This could be anything including a bash utility such as cat or an application in Node.js. The application just has to be able to read its input from STDIN. It turns out many UNIX/Linux utilities work this way already.
If you follow all the instructions in the repository you will be able to get the webhook stash up and running and invoke it like this:
# curl -X POST -v -d '{"event": "commit", "repository": "faas", "user": "alexellis"}' localhost:8080/function/func_webhookstash
You can then find the function replica with docker ps and use docker exec to inspect the file that the request was stored (stashed) in:
# docker exec webhookstash.1.z054csrh70tgk9s5k4bb8uefq find . |grep .txt
./1373526714243466079.txt
Why not create a small cloud instance on Digital Ocean to try it out and connect a Github or Slack webhook?
If you enable Docker's experimental mode you can even check out the logs of your service running on any other host in your Swarm.
docker service logs webhookstash
webhookstash.1.s8q9f2leuhx4@serverless.local.lan | Stashing request
webhookstash.2.fd7d4d7d1tp8@serverless.local.lan | Stashing request
webhookstash.1.s8q9f2leuhx4@serverless.local.lan | Stashing request
Other functions
Here are several other sample functions:
- An Alexa skill to find the hostname of the machine running the code: HostnameIntent
- An Alexa skill to find the number of Docker Captains and to Change the colour of LED smart-lights
- A simple function which returns OS-level information NodeInfo
- Use a bash or system utility as a function such as
sha256to provide a hashing service. Just use thefunctions/alpineimage and changefprocesstosha256sum.
Where next?
We still need to define the following - there are more details in the README.md file.
- How to start services (functions)
Services or functions, can be started manually, through a docker deploy stack or through the API gateway. If the services are started or run through the API gateway then some constraints need to be imposed such as a list of valid services.
- How to secure the API endpoint (if necessary)
HTTPs encryption should be implemented in the API Gateway or via Nginx with SSL termination.
The methods are designed to be invoked primarily by webhooks - so authentication may not be needed, but more care is needed around request timeouts.
- How to scale
Metrics are being recorded via Prometheus and can be accessed on the API gateway through /metrics over HTTP.
There are two modes of auto-scaling that may be appropriate - replica and infrastructure scaling.
Scaling up vs. scaling down present different problems - scaling up is easier and could be triggered through a Prometheus Alert.
With replica scaling we would monitor throughput and adjust the number of function replicas as demand increase or falls back. Infrastructure scaling could take advantage of newly open-sourced tools such as Infrakit to dynamically bring on new Swarm Mode workers on AWS, Azure or private clouds.
How can I help?
Take the solution for a spin online
You can take the code for a test-drive online through a free cloud playground called play-with-docker.com. It will take 2-5 minutes to setup with the following guide:
Fork the code and contribute your own sample function:
I have provided a number of sample functions in Go and Node.js but you can program your sample in any programming language supported by Linux - even Bash.
Take a look at the samples and create your own function such as the WebhookStash example above.
It would be great to get your feedback on Twitter, so please share:
Functions as a Service (FaaS) - a PoC for @docker Swarm Mode. https://t.co/EUO7Lli5qE #dockercaptain #serverless #containers
— Alex Ellis (@alexellisuk) January 4, 2017
Tell me what you liked/still need
This is a proof of concept - so tell me what you liked or what you still need to make this useful.